DataFormats exam preparation
This document was written by Mikoláš Fromm and contains a sum-up of all topics covered in NPRG036.
- DataFormats exam preparation
Intro
Levels of data
- Conceptual level (what the data is about)
- Logical level (how is the data structured)
- Physical level (how do the files look like)
Conceptual domain model
Answers the following questions:
- What entities are described?
- What are their properties?
- How are they connected?
Example: UML
- Class
- Attribute
- Associations between classes
Data models vs. formats vs. schemas
Models = logical view of data
- graphs - RDF, LPG
- trees - DOM, JSON
- relational - SQL database
Formats = physical view of data
- graphs - RDF = Turtle & JSON-LD & Cypher Script
- hierarchical - DOM = XML & HTML, JSON = JSON & XML
- relational - CSV, SQL DUMP
Schemas = annotations and constraints applicable to instances of data formats. For better description and validation.
- CSV = CSV on the Web
- RDF = SHACL
- JSON = JSON Schema
- XML = XML Schema
Some formats might be used as metaformats for other formats. Such as JSON is meta for GeoJSON, RDF for DCAT, XML for SVG etc...
Open vs. Closed formats
- Open = specification available on the Web, freely accessible to anyone
- Closed = specification not accessible, payment needed for access
Machine-readable formats
- Machine-readability is not a property of a format. Depends on the form of a particular data instance.
- Says whether the data is easily processed by appropriate application.
Binary vs. text based formats
- Binary = structure defined on bit by bit level, non-text files
- Text-based = contains text, chars on lines, text encoded into bits.
Standardization - authorities
- Internet Engineering Task Force (IETF)
- Internet Society (ISOC) - provide leadership in internet-related stuff
- World Wide Web Consortium (W3C) - issues recommendations
- working draft (WD)
- candidate recommendation (CR)
- proposed recommendation (PR)
- W3C recommendation (REC)
- Internet Corporation of Assigned Names and Numbers (ICANN) - IPv4 & IPv6 address space management
- MIME-Type (managed by IANA) - multipurpose internet mail extensions
- ECMA Internationl (ECMA)
RFC keywords
-
MUST, REQUIRED, SHALL
An absolute requirement -
MUST NOT, SHALL NOT
An absolute prohibition -
SHOULD, RECOMMENDED
May exist reasons to ignore -
SHOULD NOT, NOT RECOMMENDED
May exist reasons to implement
Identifiers
- U** je v ASCII
- I** je v UTF-8
- URI = Uniform resource identifier (nemusí mě nikam dostat)
- URN = Uniform resource name
- URL = Uniform resource locator (někam mě to i dostane)
- IRI = Internationalized resource identifier
- IDN = Internationalized domain name
Graph data formats
RDF
- contains set of statements in triple form: subject, predicate and object
ex:catalog rdf:type dcat:Catalog - statements cant be drawn graphically.
- no ordering in the triples
- typed literals
"2020-04-23"^^xsd:date - language tags
"Oscar Magnuson"@en - blank nodes (if no-one would ever want to link to this data):
my:staff/85740 my:hasAdress _:a1 .
_:a1 my:street "Františka Lenocha 1" .
_:a1 my:city "Prague" .
_:a1 my:zipCode "11000" .
RDF - serialization
N-Triples
- basically as a RDF, only extended with
# comemnts
Turtle
- extended with prefixes
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix my: <http://example.com/> .
my:index.html dcterms:created "2020-04-23"^^xsd:date .
- supports relative prefixes:
- if no
@basedefined, taken implicitly from document URL
@prefix foo: <http://example.org/ns#> .
@base <http://newbase.com/> .
<#document> foo: <https://jk.com> .
is equivalent with:
<http://newbase.com/#document> <http://example.org/ns#> <https://jk.com> .
- prefixes can be joined together
@base <http://example.org/ns/> . (base = http://example.org/ns/)
@base <foo/> . (base = http://example.org/ns/foo/)
@prefix : <bar#> . (: = http://example.org/ns/foo/bar#)
- extended with
;for short-cutting - extended with multiline strings
"""a string
with newlines
"""
- extended with blank nodes written simply in
[...] - if some metadata needs to be stores, each statement can be a next RDF triple with
rdf:subject,rdf:predicateandref:obejct=> REIFICATION, is 4x more space complex - or named graphs can be used. Extends RDF to quads
Subject Predicate Object Graph - RDF TriG RDF Turtle, but with named graph support:
base <http://www.w3.org/People/> .
@prefix : <http://xmlns.com/foaf/0.1/> .
# default graph
{
ericFoaf:ericP :givenName "Eric" .
}
# also default graph, no {}
ericFoaf:ericP :givenName "Eric" .
# graph highlight
GRAPH <Eric/ericP-foaf.rdf> {
ericFoaf:ericP :givenName "Eric" .
}
RDF Schema
- Vocabulary for creating other RDF vocabularies
- classes:
ex:MotorVehicle rdf:type rdfs:Class .
ex:Van rdf:type rdfs:Class .
ex:PassengerVehicle rdfs:subClassOf ex:MotorVehicle .
ex:Van rdfs:subClassOf ex:MotorVehicle .
ex:MiniVan rdfs:subClassOf ex:Van .
- properties (are first class citizens => can live independently of any calss)
ex:Person rdf:type rdfs:Class .
ex:author rdf:type rdf:Property . ## means that author is a property
ex:author rdfs:range ex:Person . ## means that each author is of type ex:Person
ex:hasMother rdf:type rdf:Property .
ex:hasMother rdfs:range ex:Female .
ex:hasMother rdfs:domain ex:Person . ## means that every Person has a mother
rdfs:labelandrdfs:commentare included toordf:Listfor closed collections that keep ordering
rdf:firstfor the first item,rdf:restfor the next node. Last item isrdf:nil.- syntax sugar for lists:
:subject :predicate (:a :b :c) rdf:Bag,rdf:Seq,rdf:Altare open collections, where adding next node is only made withmy:bag rdf:_3 my:item3.- Open World Assumption adds unknown option for answers to the questions that have no source data.
World Wide Web
- Should solve the problem of working with unknown data of unknown scheme with unknown context.
- HTML as format for publishing documents
- URLs as unique global identifiers of documents
- HTTP for localization and accessing documents by their URLs
- hyperlinks between documents
- Why current web is not Web of Documents:
- no unique global identifiers of things
- many formats for publishing data (XML, JSON, CSV, XLS)
- HTTP for localization of APIs and accessing them (but not for localization of things and accessing their data)
- current formats dont enable linking related entities
- Linked data ~ Web of Data
- principles of linked data:
- Use URIs as names for things
- Use HTTP URIs for looking up the names
- Provide useful information when looking up some URI (formats etc...)
- Include links to other URIs to discover more (Wikipedia does this)
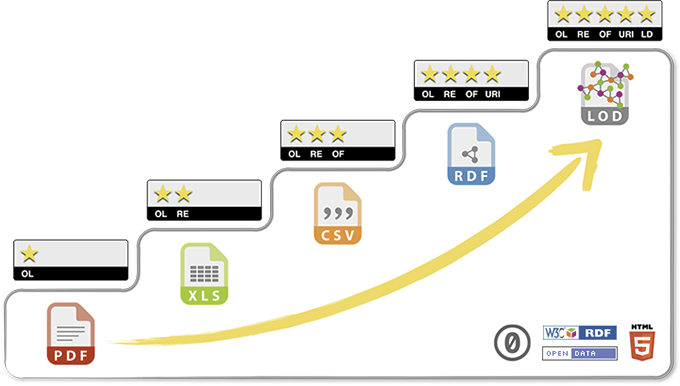
5 star principle
SPARQL
- query language for RDF data
- queries in the following format:
<http://example.com/index.html> <http://purl.org/dc/terms/creator> <http://example.com/staff/8574> .
?s <http://purl.org/dc/terms/creator> <http://example.com/staff/8574> .
- will return all subjects that match the pattern. Or more complicated example:
?stud rdf:type sis:Person ;
sis:name ?name ;
sis:age ?age .
- all parts of the query must be matched, therefore Person without age will be omitted. But it can be marked
OPTIONAL
?stud sis:name ?name ;
sis:age ?age .
OPTIONAL {
?stud rdf:type ?type.
}
- can also specify the output columns and filter by their values
PREFIX sis: <http://is.cuni.cz/studium/sis#>
SELECT ?name ?age
WHERE {
?stud a ?type ;
sis:name ?name ;
sis:age ?age .
FILTER (?age > 27)
}
prefixandbasework same as in RDF.- since we have introduced
quadstoo, the SPARQL forquadslooks like:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT DISTINCT ?g
WHERE {
GRAPH ?g {
?s a foaf:Person .
}
}
- there are also some aggregation functions:
COUNT,SUM,AVG,MIN,MAX,SAMPLE,GROUP_CONCAT(?x ; separator="|") - can also bind some values into another value:
SELECT ?check ?fine ?higher
WHERE {
?check a schema:CheckAction ;
schema:result/schema:result/gr:hasCurrencyValue ?fine .
BIND(IF(?fine > 1000, true, false) AS ?higher)
}
LIMIT 100
- function
CONSTRUCTis available for creating new RDF tuples.
Common RDF Vocabularies
Dublin Core
- The original core, having dc: prefix and dcterms: prefix
SKOS
- simple knowledge organization system
- codelists, taxonomies
skos:prefLabel,skos:altLabel,skos:hiddenLabelskos:broaderTransitive,skos:narrowerTransitivehas then automaticallyskos:broaderandskos:narrowerassigned.skos:exacthMatch(transitive),skos:closeMatch(not transitive)
Good Relations
- Vocabulary for E-Commerce, industry neutral
- Agent
gr:BusinessEntity - Object or Service
gr:ProductOrService - Promise
gr:Offering - Location
gr:Location
Schema.org
- trying to import all schemas from all other vocabularies
- founded by Google, Microsoft, Yahoo...
- usually too general, easier to create, harder to work with
WikiData
- like wikipedia, but for facts instead of documents
- queryable via SPARQL endpoint
- WikiData is an instance of a WikiBase
- P-numbers (predicate) and Q-numbers (object)
Labeled Property Graph (LPG)
- ideal for representing things where the relation to other objects is the primary information
- usually used when relation is more important than the object itself
- example usage:
- connected entities
- self-referencing
- unbounded hierarchies
- discovering different paths
- not having any schema that would specify requirements for each object
- is oriented multigraph
- edges have labels
- nodes have labels
- nodes and edges have set of key-value properties
Create statements
CREATE (:Person {name: 'James'})-[:FOLLOWS]->(:Person {name: 'John'})
Queries
MATCH
(p1:Person)-[:USES]->(c:Camera)<-[:OWNS]-(p2:Person)<-[:FOLLOWS]-(p1:Person)
RETURN
p1
- results can be modified:
//Find James’s camera
MATCH // matches all types that have the same structure
(c:Camera)<-[:OWNS]-(p:Person)
WHERE // typical conditioning
p.name = 'James'
SET // changing the output
c.condition = 'used'
RETURN
c
- there is a difference between
CREATEandMERGE
MERGE (p:Person {name: 'James'}) // will only be created if James doesn't exist yet
ON CREATE SET // only when object was created
p.twitter = '@james'
MERGE (p)-[:OWNS]->(:Laptop {vendor: 'Dell'})
-
Node labels: UpperCamelCase
-
Relationship types: SCREAMING_SNAKE_CASE
-
Property keys: lowerCamelCase
-
Cypher keywords: case insensitive
-
contains aggregates implicitly without GROUP BY statement:
MATCH (p:Person)-[:ACTED_IN]->(m:Movie)
RETURN p.name, count(*) AS numberOfMovies // is grouped by name, aggregation is count(*)
- has
WITHstatement for manipulating content before returning
MATCH (david {name: 'David'})--(otherPerson)-->()
WITH otherPerson, count(*) AS foaf
WHERE foaf > 1
RETURN otherPerson.name
// Names of people (otherPerson) connected to David, who have more than 1 outgoing connections.
- can be load from CSV
LOAD CSV WITH HEADERS FROM 'file:///orders.csv' AS row
WITH toInteger(row.orderID) AS orderId, // toInteger() otherwise everything is string
row.`ship country` AS country // because of "WITH HEADERS", the column names are recognized
MERGE (o:Order {orderId: orderId})
SET o.shipCountry = country
RETURN count(o);
- Neo4j Graph Data Science Library (GDS): contains many popular graph algorithms in the most effective implementation
RDF vs LPG
| RDF | LPG |
|---|---|
| global identification | local node labels & edge types |
| globally reused RDF vocabs | relationship types and node labels always different |
| focused on linking data of various publishers | focused on evaluating graph algorithms |
Hierarchical data formats
XML
- hierarchial model that has only one root and its children
Document oriented XML
- text-based document focused on the message of the document that should remain human-readable, but adds position tags of important information for machine-readability
<?xml version="1.0" encoding="UTF-8"?>
<message>
Dear <customer><firstName>John</firstName> <lastName>Doe</lastName></customer>,
the balance on your bank account <accountNumber>111333444/1123</accountNumber> as of <balanceDate>3rd of January 2021</balanceDate> is <balance><value>25000</value> <currency>CZK</currency></balance>.
Best regards,
<bankName>Your bank</bankName>
<streetAddress>1234 5th Avenue</streetAddress>
<phone>+420123456789</phone>
</message>
Data oriented XML
- root must be empirically chosen
- if all elements are removed, non-human-readable message is returned
<?xml version="1.0" encoding="UTF-8"?>
<catalog>
<title>My catalog</title>
<description>This is my dummy catalog</description>
<contact-point>
<name>John Doe</name>
<e-mail>mailto:john@doe.org</e-mail>
</contact-point>
<datasets>
<dataset>
<title>My first dataset</title>
</dataset>
<dataset>
<title>My second dataset</title>
</dataset>
</datasets>
</catalog>
- every document has:
- Prolog
<?xml version="1.0" encoding="UTF-8"?> - Start tag with corresponding End tag
<element>...</element> - Comments
<!-- XML declaration --> - Attributes
<element attribute1="value" attribute2="another value">...</element>
- Prolog
XML Well-formedness
- if document complies with all XML syntax rules:
- case match
- proper opening and ending of elements
- single root element
- correct nesting
- has nothing to do with XML schema and its data inside!
XML namespaces
- to distinguish elements with same name, namespacing is defined:
<root xmlns:h="http://www.w3.org/TR/html4/"
xmlns:f="https://www.w3schools.com/furniture">
<h:table>
<h:tr>
<h:td>Apples</h:td>
<h:td>Bananas</h:td>
</h:tr>
</h:table>
<f:table>
<f:name>African Coffee Table</f:name>
<f:width>80</f:width>
<f:length>120</f:length>
</f:table>
</root>
f:tableis now different fromh:table- namespace is valid in the whole subspace of the current node.
XML language specification (xml:lang)
<?xml version="1.1" encoding="UTF-8"?>
<document>
<p xml:lang="en">The quick brown fox jumps over the lazy dog.</p>
<p xml:lang="en-GB">What colour is it?</p>
<p xml:lang="en-US">What color is it?</p>
<sp who="Faust" desc='leise' xml:lang="de">
<l>Habe nun, ach! Philosophie,</l>
<l>Juristerei, und Medizin</l>
<l>und leider auch Theologie</l>
<l>durchaus studiert mit heißem Bemüh'n.</l>
</sp>
</document>
- values of the attributes are basically the same as in RDF
XML processing instruction (PI)
<?xml-stylesheet type="text/xsl" href="style.xsl"?>
- not visible in the document, only used by the processing programs
- prolog is not a PI
XML entities
< <
> >
& &
' '
" "
< < - decimal
< < - hexadecimal
- used for escaped characters, same as in HTML
Example usage
- should not represent tabular data (use CSV instead)
<consumers>
<consumer>
<name>John</name>
<age>20</age>
<coffees-per-day>2</coffees-per-day>
</consumer>
<consumer>
<name>Jane</name>
<age>18</age>
<coffees-per-day>1</coffees-per-day>
</consumer>
<consumer>
<name>Steve</name>
<age>31</age>
<coffees-per-day>5</coffees-per-day>
</consumer>
</consumers>
- should represent hierarchical data with attributes
<Companies>
<Company>
<Identifier recorded="2014-11-05">3543609</Identifier>
<Address type="HQ" recorded="2014-11-05">
<countryName>Česká republika</countryName>
<city>Brno</city>
<partOfCity>Bohunice</partOfCity>
<street>Neužilova</street>
<descNumber>201</descNumber>
<orNumber>35</orNumber>
<zip>62500</zip>
<region>Brno-město</region>
</Address>
</Company>
</Companies>
- used in:
- Microsoft Office
- SVG
- RSS
Processing XML
Document object model (DOM)
- loads the entire XML into memory
- does not support streams
- impossible to work with large documents
- supports random access
XPath /consumers/consumer[1]/name
Simple API for XML (SAX)
- processes the XML file as a stream of events
- works with streams
- works with large files
- does not support random access
Element start (name = "consumers")
Element start (name = "consumer")
Element start (name = "name")
Text value (value = "John")
.
.
.
- has StAX alternative that allows user to stop when done
XML Syntax (RDF/XML)
- the oldest RDF serialization
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF
xmlns:dcterms="http://purl.org/dc/terms/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
>
<rdf:Description rdf:about="http://example.com/index.html">
<dcterms:subject xml:lang="en">Education</dcterms:subject>
<rdf:type rdf:resource="http://xmlns.com/foaf/0.1/Page"/>
</rdf:Description>
</rdf:RDF>
- supports blank nodes:
<rdf:RDF …>
<rdf:Description rdf:about="SubjectResource">
<PredicateResource rdf:nodeID="BlankNode"/>
</rdf:Description>
<rdf:Description rdf:nodeID="BlankNode">
…
</rdf:Description>
…
</rdf:RDF>
XML Schema
- is a well-formed XML document
- each XML document can be linked to the schema:
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
... <!-- XML schema definition --> …
</xs:schema>
<?xml version="1.0" encoding="utf-8"?>
<root_element_of_XML_document
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="schema2.xsd">
... <!-- XML document --> …
</root_element_of_XML_document>
XML Validation
- document is valid <=> it validates against an XML schema
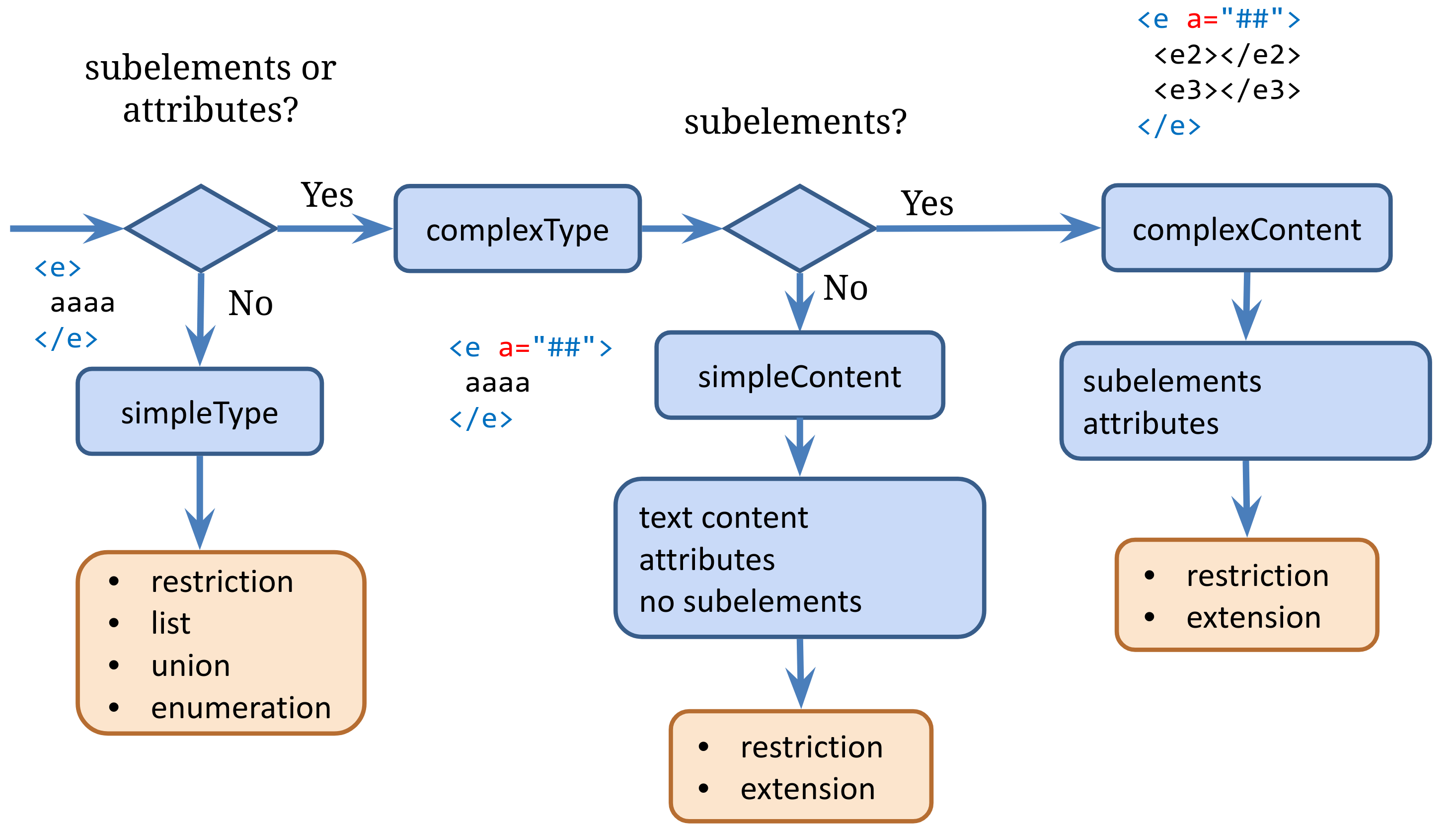
- XML Schema 1.x defines simple data types
- having definitions of:
- DataTypes (simpleType, complexType)
- Elements (group of elements)
- Attributes (groups of attributes)
- having the following basic schema:
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="Catalog"/>
</xs:schema>
valid
<?xml version="1.0" encoding="UTF-8"?>
<Catalog
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="Schema01.xsd"
>
<Dataset>
<test/>
</Dataset>
</Catalog>
<?xml version="1.0" encoding="UTF-8"?>
<Catalog
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="Schema01.xsd"
/>
not valid
<?xml version="1.0" encoding="UTF-8"?>
<Catalog1
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="Schema01.xsd"
/>
- schema does not contain definition for
Catalog1
simpleType & complexType
Namespacing
schema schema.xsd
<xs:schema
xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://tempuri.org/"
elementFormDefault="qualified">
<xs:element name="Add">
<xs:complexType>
<xs:sequence>
<xs:element name="intA"
type="xs:int"/>
<xs:element name="intB"
type="xs:int"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
document document.xml
<?xml version="1.0" encoding="UTF-8"?>
<n1:Add
xmlns:n1="http://tempuri.org/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://tempuri.org/ schema.xsd">
<n1:intA>1</n1:intA>
<n1:intB>3</n1:intB>
</n1:Add>
- two types of elements
- qualified
- unqualified
schema.xsd
<xs:element name="intA" type="xs:int"
form="unqualified"/>
<xs:element name="intB" type="xs:int"
form="qualified"/>
document.xml
<intA>1</intA>
<n1:intB>3</n1:intB>
Xpath
- query language over XML document
XPath Data Model
- data model into which the XML document is transformed and on which the queries are performed
- each element can have:
- another elements
- attributes
- value
Xpath examples
absolute path:
/catalog/datasets/dataset/title
access function:
/catalog/datasets/dataset/title/text()
access attribute
/catalog/datasets/dataset/title/@xml:lang
filter with predicate
/catalog/datasets/dataset/title[@xml:lang="en"]/text()
relative path -> is taken from the current position
title[@xml:lang="en"]/text()
axes:
axis::node-test [predicate1] ... [predicateN]
child: (contains all child elements only)
/child::catalog/child::datasets
descendant: (contains all elements in the subtree)
/catalog/descendant::*
attribute: (contains all attributes in the subtree)
/catalog/descendant::*/@*
preceding-sibling: (contain a preceding sibling of the node)
/catalog/title/preceding-sibling::title/text()
descendant-or-self: (contains all current or descendant elements)
/catalog//title
- document order is according to the position of the start tag of elements in the document
functions:
name() - returns the name of the element
/catalog/datasets/name()
position() - returns the position in the parent
/catalog/datasets/dataset/position()
last() - returns the last position in the parent
/catalog/datasets/dataset[last()]
Common errors
- return type mismatch:
/rental[state="Hawaii"]/offer/car[type="cabrio"]
vs.
/rental[state="Hawaii" and offer/car[type="cabrio"]]
//section[last()]
/descendant-or-self::node()/section[last()] (: returns end section of each chapter :)
vs.
/descendant::section[last()] (:returns last section:)
XSL Transformations - XSLT
- used to generate (for example) HTML document from Data-oriented XML
- input = XML document
- output = any text file
empty stylesheet
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:fn="http://www.w3.org/2005/xpath-functions">
<xsl:output method="html" encoding="UTF-8" indent="yes" />
</xsl:stylesheet>
Examples
first example: selecting informations via xsl:value-of
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:fn="http://www.w3.org/2005/xpath-functions">
<xsl:output method="html" encoding="UTF-8" indent="yes" />
<xsl:template match="catalog">
<html>
<head>
<title>
<xsl:value-of select="title[@xml:lang='en']"/>
</title>
</head>
<body>
<h1>
<xsl:value-of select="title[@xml:lang='en']"/>
</h1>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
<html xmlns:fn="http://www.w3.org/2005/xpath-functions" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>My catalog</title>
</head>
<body>
<h1>My catalog</h1>
</body>
</html>
second example
<!-- gets applied only to selected elements -->
<xsl:apply-templates select="datasets/dataset">
- anything else expect the root element won't be processed without specifying the following statement.
- it tells the processor to apply templates to all children of the current node
Implicit templates
The following templates are implicitly in XSLT:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:fn="http://www.w3.org/2005/xpath-functions">
<!-- match all elements and its children -->
<xsl:template match="*|/">
<xsl:apply-templates/>
</xsl:template>
<!-- match all text content of elements -->
<xsl:template match="text()|@*">
<xsl:value-of select="."/>
</xsl:template>
<!-- match all instructions and comments -->
<xsl:template match="processing-instruction()|comment()"/>
</xsl:stylesheet>
therefore explicit override of the implicit template is needed:
<xsl:template match="text()"/>
Templates can be also named and have parameters:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:fn="http://www.w3.org/2005/xpath-functions">
<xsl:output method="html" encoding="UTF-8" indent="yes" />
<!-- matches the dataset and passes the correct arguments -->
<xsl:template match="dataset">
<xsl:call-template name="processTitle">
<xsl:with-param name="element">h2</xsl:with-param>
<xsl:with-param name="lang">en</xsl:with-param>
</xsl:call-template>
</xsl:template>
<!-- generic definition with two arguments, element and lang -->
<xsl:template name="processTitle">
<xsl:param name="element" required="yes"/>
<xsl:param name="lang" required="yes"/>
<xsl:element name="{$element}">
<xsl:value-of select="title[@xml:lang=$lang]"/>
</xsl:element>
</xsl:template>
</xsl:stylesheet>
JSON
- media type: application/json
- basic type: JSON String
- using \ for escaping
- support for decimal numbers
- whitespaces are ignored
- JSON values:
- string
- number
- object
- array
- true / false
- null
Example usage
- WebAPI
- Czech POI
- Apache CouchDB
JSON Lines
- something between CSV and JSON
- each line contains a valid JSON line
- is created for reading JSON line by line
JSON Pointer
- ability to point to an arbitrary value in a JSON document
- pointer represented as JSON String or URI fragment
JSON Schema
Basic validation
having the following file:
{
"productId": 1,
"productName": "A green door",
"price": 12.5,
"tags": [ "home", "green" ],
"dimensions": {
"length": 7.0,
"width": 12.0,
"height": 9.5
}
}
the schema might look like:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "http://example.com/product.schema.json",
"title": "Product",
"description": "A product from Acme's catalog",
"type": "object",
"properties": {
"productId": {
"description": "The unique identifier for a product",
"type": "integer"
},
"productName": {
"description": "Name of the product",
"type": "string"
},
"price": {
"description": "The price of the product",
"type": "number",
"exclusiveMinimum": 0
},
"tags": {
"description": "Tags for the product",
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true
},
"dimensions": {
"type": "object",
"properties": {
"length": { "type": "number" },
"width": { "type": "number" },
"height": { "type": "number" }
},
},
"required": [ "productId" ]
}
Tuple validation
JSON Arrays can be validated with tuple validation:
{
"type": "array",
"prefixItems": [
{ "type": "number" },
{ "type": "string" },
{
"type": "string",
"enum": ["Street", "Avenue", "Boulevard"]
},
{
"type": "string",
"enum": ["NW", "NE", "SW", "SE"]
}
],
"additionalItems": false
}
where valid data are:
[1600, "Pennsylvania", "Avenue", "NW"]
[10, "Downing", "Street"]
and non-valid are:
[24, "Sussex", "Drive"]
["Palais de l'Élysée"]
[1600, "Pennsylvania", "Avenue", "NW", "Washington"]
Schema can be defined externally:
...
"properties": {
...
"warehouseLocation": {
"description": "Coordinates of the warehouse ...",
"$ref": "https://example.com/geographical-location.schema.json"
}
...
}
...
String formats validation
JSON Schema also support string format validation. Following formats are available:
- date-time, date, time, duration
- email, idn-email
- hostname, idn-hostname
- ipv4, ipv6
- uri, uri-reference
- iri, iri-reference
- uuid
- uri-template,
- json-pointer, relative-json-pointer
- regex
JSON-LD
- JSON serialization for RDF Turtle
- data enhanced with context for RDF transformation
{
"@context":{
"name": "http://schema.org/name",
"image": {
"@id": "http://schema.org/image",
"@type": "@id"
},
"homepage": {
"@id": "http://schema.org/url",
"@type": "@id"
}
},
"name": "Manu Sporny",
"homepage": "http://manu.sporny.org/",
"image": "http://manu.sporny.org/images/manu.png"
}
Subject identifier
- What RDF subject is it?
"@id": "http://me.markus-lanthaler.com/"part
Type/Class identifier
- Of what type is the subject?
"@type": "http://schema.org/Restaurant"or with multiple values"@type": [ "http://schema.org/Restaurant", "http://schema.org/Brewery" ]
Base IRI
- can define base IRI which is later used thoughout the whole document
when"@base": "http://example.com/document.jsonld"
then"@id": ""==http://example.com/document.jsonld
Compact IRI
- same as in RDF, prefixing can be done on all places where IRI is expected
{
"@context":
{
"foaf": "http://xmlns.com/foaf/0.1/"
...
},
"@type": "foaf:Person"
"foaf:name": "Dave Longley",
...
}
JSON languages
{
"@context": {
...
"ex": "http://example.com/vocab/",
"@language": "ja", // default for the whole document
"name": { "@id": "ex:name", "@language": null }, // should not have language tag
"occupation": { "@id": "ex:occupation" }, // not required
"occupation_en": { "@id": "ex:occupation", "@language": "en" }, // predefined EN
"occupation_cs": { "@id": "ex:occupation", "@language": "cs" } // predefined CS
},
"name": "Yagyū Muneyoshi",
"occupation": "忍者",
"occupation_en": "Ninja",
"occupation_cs": "Nindža",
...
}
JSON Lists
- RDF has no default list order, whereas JSON has.
{
...
"@id": "http://example.org/people#joebob",
"nick": [ "joe", "bob", "JB" ], // does not keep the order
...
}
{
...
"@id": "http://example.org/people#joebob",
"nick":
{
"@list": [ "joe", "bob", "jaybee" ] // keeps the order
},
...
}
Relational data formats
SQL dump
- script that typically drops any existing tables and then creates new tables
Delimiter-Separated Values (DSV)
- most generic, delimiter not specified
- comes from UNIX
- actually should be separator-separated values
Tab-Separated Values (TSV)
- already has own media (MIME) type
- \t can't be used in the content
Comma-Separated Values (CSV)
- default encoding: US-ASCII
- line ending: CRFL
- column separator: ,
- escape character: "
- escaped escape character: ""
- content-type: text/csv;charset=utf-8;header=present
URL in CSV
- https://www.example.com/data.csv#col=2
- https://www.example.com/data.csv#row=2
- https://www.example.com/data.csv#cell=4,1
CSV on the Web (CSVW)
- schema for CSV file
main entities in the model:
- table group
- table
- row
- column
- cell
example of schema describing columns, rows and cells:
{
"@context": ["http://www.w3.org/ns/csvw", {"@language": "en"}],
"@type": "Table",
"@id": "https://example.org/table1",
"url": "https://example.org/table1.csv",
"tableSchema": {
"columns": [{
"name": "airport", // URI compatible name
"titles": "letiště",
"datatype": "string"
}, {
"name": "continent", // URI compatible name
"titles": "kontinent",
"datatype": "string"
}],
"primaryKey": "airport",
// reference to the other table below
"foreignKeys": [{
"columnReference": "airport",
"reference": {
"resource": "https://example.org/table1.csv",
"columnReference": "airport"
}
}]
}
}
Where to find the CSVW metadata?
- user provided
- Linked HTTP header
- /.well-known/csvw
- appended *-metadata.json to the URL of the CSV file
- csv-metadata.json relative URL
Key-Value formats
.properties file
- ISO-8859-1
- is simply a hash-table
- used in Java
INI file
- from MS-DOS
- gradually replaced by Windows Registry
- only two level hashtable
dbsetting.ini example:
; last modified 1 April 2001 by John Doe
[owner]
name=John Doe
organization=Acme Widgets Inc.
[database]
; use IP address in case network name resolution is not working
server=192.0.2.62
port=143
file="payroll.dat"
TOML
- "config file format for humans"
- UTF-8
- has native datatypes
- maps to (nested) hashtables
- multiline string support
- int, float, hexa, octal, binary, nan, inf number support
# This is a TOML document
title = "TOML Example"
[owner]
name = "Tom Preston-Werner"
dob = 1979-05-27T07:32:00-08:00
[database]
enabled = true
ports = [ 8000, 8001, 8002 ]
data = [ ["delta", "phi"], [3.14] ]
temp_targets = { cpu = 79.5, case = 72.0 }
[servers]
[servers.alpha]
ip = "10.0.0.1"
role = "frontend"
[servers.beta]
ip = "10.0.0.2"
role = "backend"
YAML
- same motivation as for TOML
- every JSON is already YAML
- indentation matters!
---
# An employee record
name: Martin D'vloper
job: Developer
skill: Elite
employed: True
foods:
- Apple
- Orange
- Strawberry
- Mango
drinks: ['Coke', 'Sprite']
languages:
perl: Elite
python: Elite
pascal: Lame
motto: > # ignores the newlines
make hey,
while the sun shines
education: | # preserves newlines
4 GCSEs
3 A-Levels
BSc in the Internet of Things
---
key can be a complex type:
---
# key
?
- "Detroit Tigers"
- "Chicago cubs"
:
# value
- 2001-07-23
---
# key
?
- "New York Yankees"
- "Atlanta Braves"
:
# value
- 2001-07-02
- 2001-08-12
- 2001-08-14
---
supports anchors and aliases:
-
center: &ORIGIN {x: 73, y: 129} # definition
radius: 7
-
start: *ORIGIN # alias reuse
finish: { x: 89, y: 102 }
-
start: *ORIGIN
color: 0xFFEEBB
text: Pretty vector drawing.
Text document formats
Plain text
- various line endings
- encoding must be specified
- mediatype: text/plain
Rich text
- specification for extremely simple, extensible syntax
- added <bold>, <italics> etc.
- mediatype: text/richtext
Enriched text
- evolution of richtext
- parallel to HTML
- used primarly for emails
- mediatype: text/enriched
Rich Text Format (RTF)
- developed by Microsoft
- proprietary format inspired by TeX
- uses Windows-* encodings
- mediatype: text/rtf
602
- created by Software602
- uses ASCII controlling characters for formatting
- has .602 extension
HTML
- mediatype: text/html
- we all know HTML...
Markdown
- markup-language:
- readability of source code by humans
- easy conversion into HTML
- mediatype: text/markdown
- has many flavours
- each .md syntax object has mapping into .html element
CommonMark
- unambiguous syntax specification for Markdown
- includes hardline breaks
- codeblocks marked as ``` at the beginning and ending
Wikitext
- no formal specification
- focused on proper linking:
links:
[[copy edit]]
[[copy edit]]ors
[[Android (operating system)|Android]]
[[Frog#Locomotion|locomotion in frogs]]
https://www.wikipedia.org
[https://www.wikipedia.org]
[https://www.wikipedia.org/ Wikipedia]
result in:
copy edit
copy editors
Android
locomotion in frogs
https://www.wikipedia.org
[1]
Wikipedia
TeX
- high-quality books with minimal effort
- giving exactly the same output on all computers
- is basically a standard for publications in technical fields
- end-users not work with TeX, only developers that write TeX packages
LaTeX
- bundle of TeX macros
- used by endusers
- let author not think about formating
- supports cross-reference, tables, figures etc.
- generated PDF at the end
simple document:
\documentclass{article}
\usepackage{amsmath}
\usepackage[utf8]{inputenc}
\title{First document}
\author{Oscar Magnuson}
\date{January 2024}
\begin{document}
\maketitle
Hello world!
\[
\binom{n}{k} = \frac{n!}{k!(n-k)!}
\]
\end{document}
supports many sections:
\part{name} % not in article
\chapter{name} % not in article
\section{name}
\subsection{name}
\subsubsection{name}
\paragraph{name}
\subparagraph{name}
\section*{name} % not numbered
support lists:
% unordered
\begin{itemize}
\item One
\item Two
\item Three
\end{itemize}
% ordered
\begin{enumerate}
\item One
\item Two
\item Three
\end{enumerate}
referencing:
\section{Introduction}
\label{section:Intro}
First document. This is a simple example, with no
extra parameters or packages included.
\subsection{Subsection}
As we could see in \autoref{section:Intro},
Multimedia formats
Single-media
Graphics
Vector graphics
- points, pahts, text
- SVG
- XML based, supported by all major web browsers
- can be embedded in HTML and styled with CSS
- editors:
- Inkspace,
- Adobe Illustrator
- Universal 3D (U3D)
- vertex based 3D graphics format
- can be embedded into PDF
Rastr graphics
- pixel / dot
- pixel is the resolution of the source image
- dot is the resolution of dots in the printer
- pixel can be:
- monochrome
- grayscale
- palletized
- full color
Color models
- RGB:
- how strongly must each light source shine
- RGBA:
- added alpha channel for transparency
- CMYK:
- how much ink of each color must be applied
- Colorspace:
- all colors that are visible by human eye, preserves distance between colors
- each model is a subset of the colorspace
- gamut ~ how much of the colospace is the model able to cover
- bit-depth: how much bits represent each pixel
- dithering: neighbouring pixels have only basic colors, it seems as only one color from a distance
- printers have 4-color 4800 DPI, therefore 1200 DPI effectively
BMP - Device-independent bitmap
- bytes that represent the image, pixel by pixel
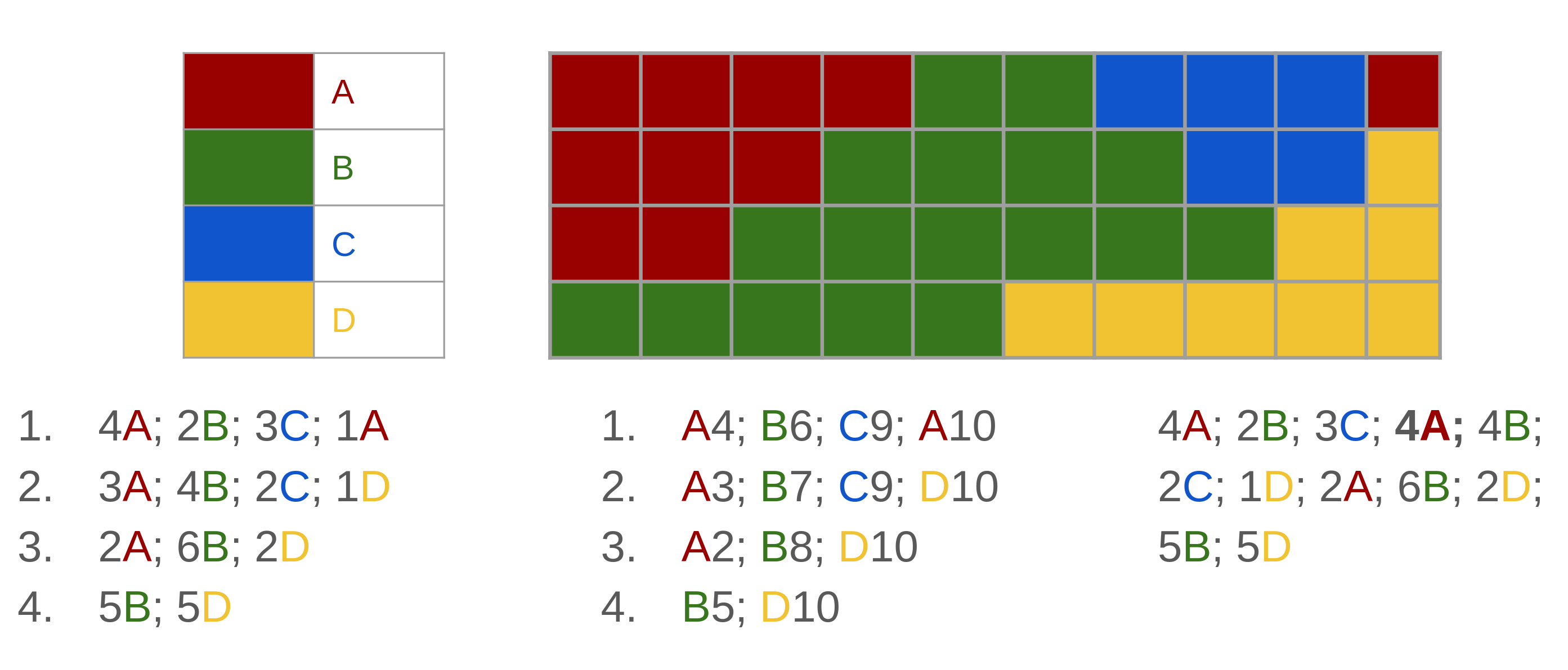
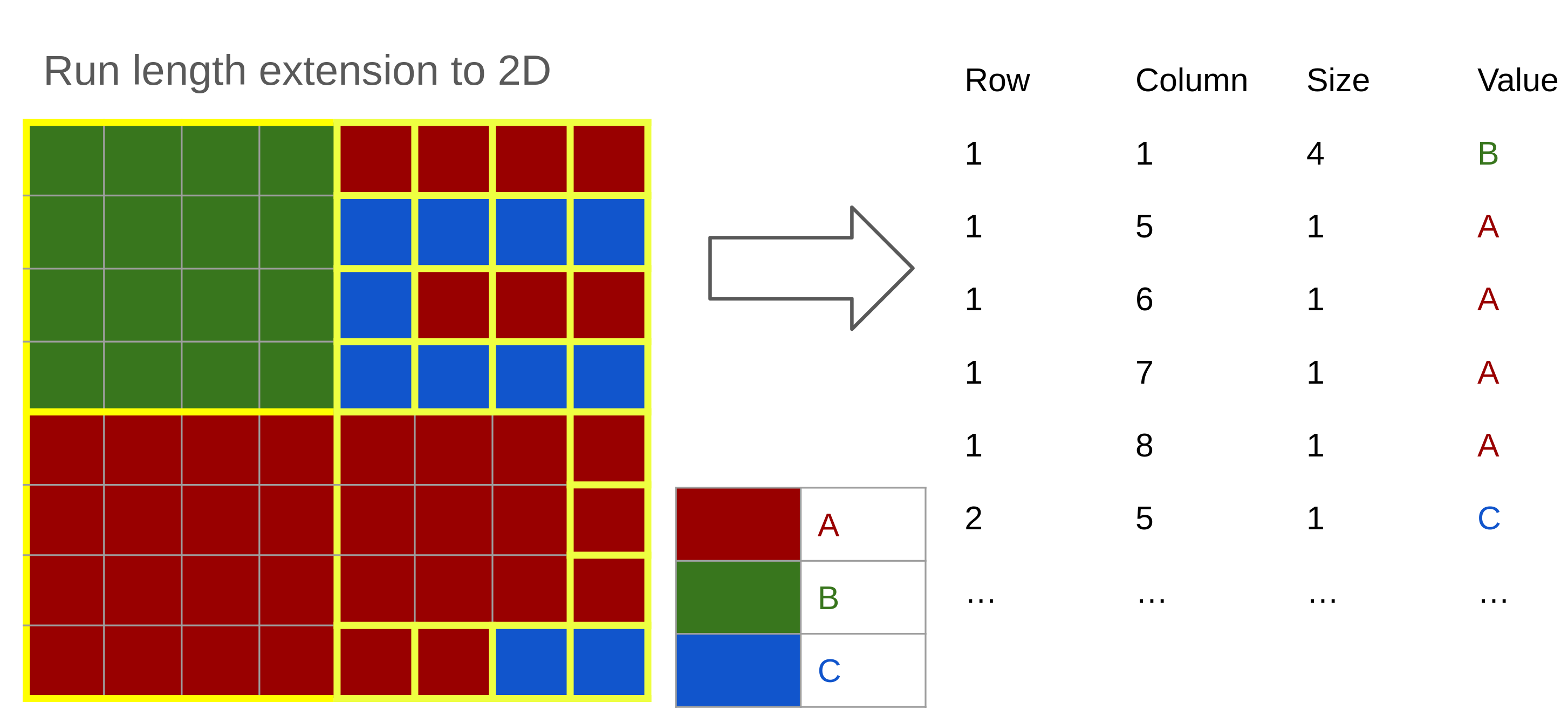
Run length coding
Blockwise coding
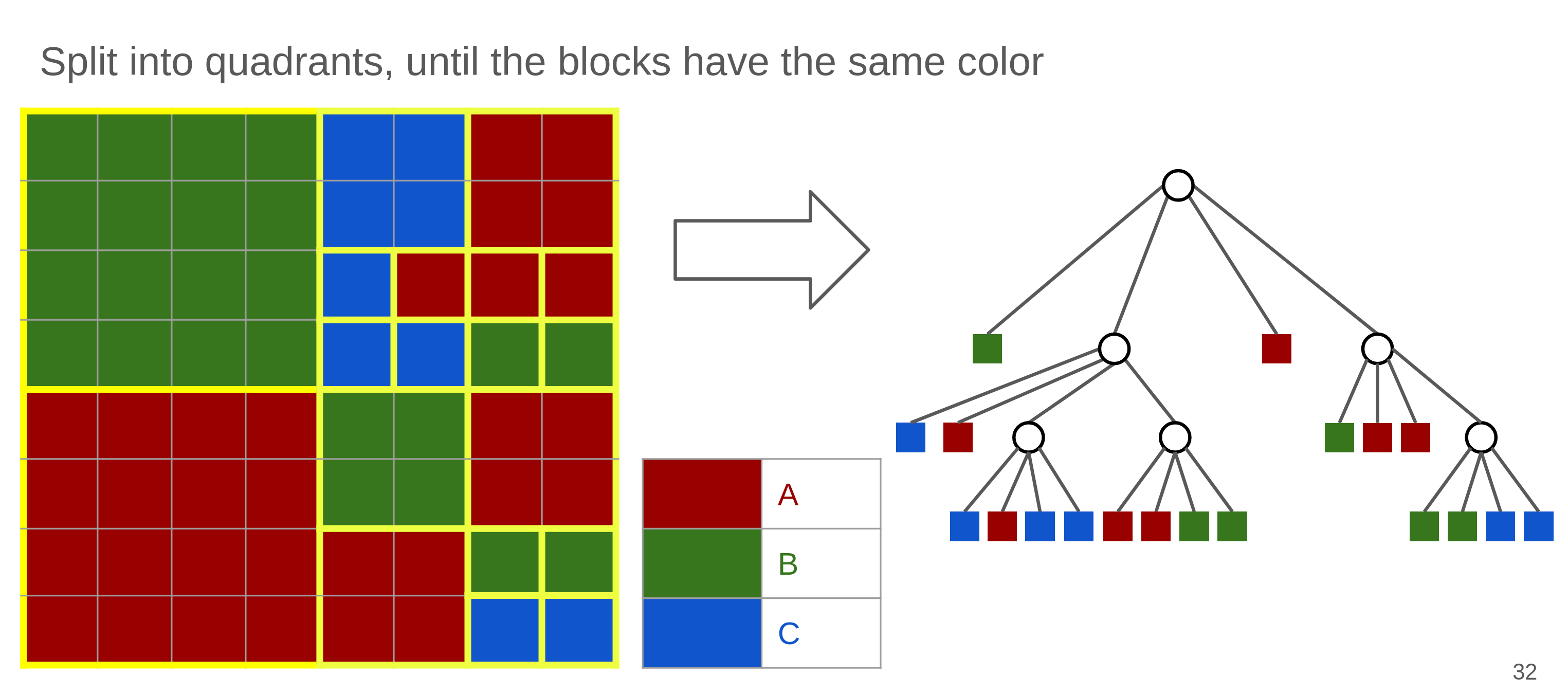
QuadTree coding
Raster formats with lossless compression
- GIF
- chooses 8 bit per pixel for each image
- supported animation
- PNG
- full RGBA model
- animation not supported
Raster formats with lossy compression
- any image can be transformed into sum of cosine function series, that are easily represented
- quantization:
- some frequencies are ignored in the picture
- chroma subsampling
- using Y'CbCr model
- Y' = lumma
- Cb = chroma blue
- Cr = chroma red
- human eye is more sensitive to luma changes than to chroma changes
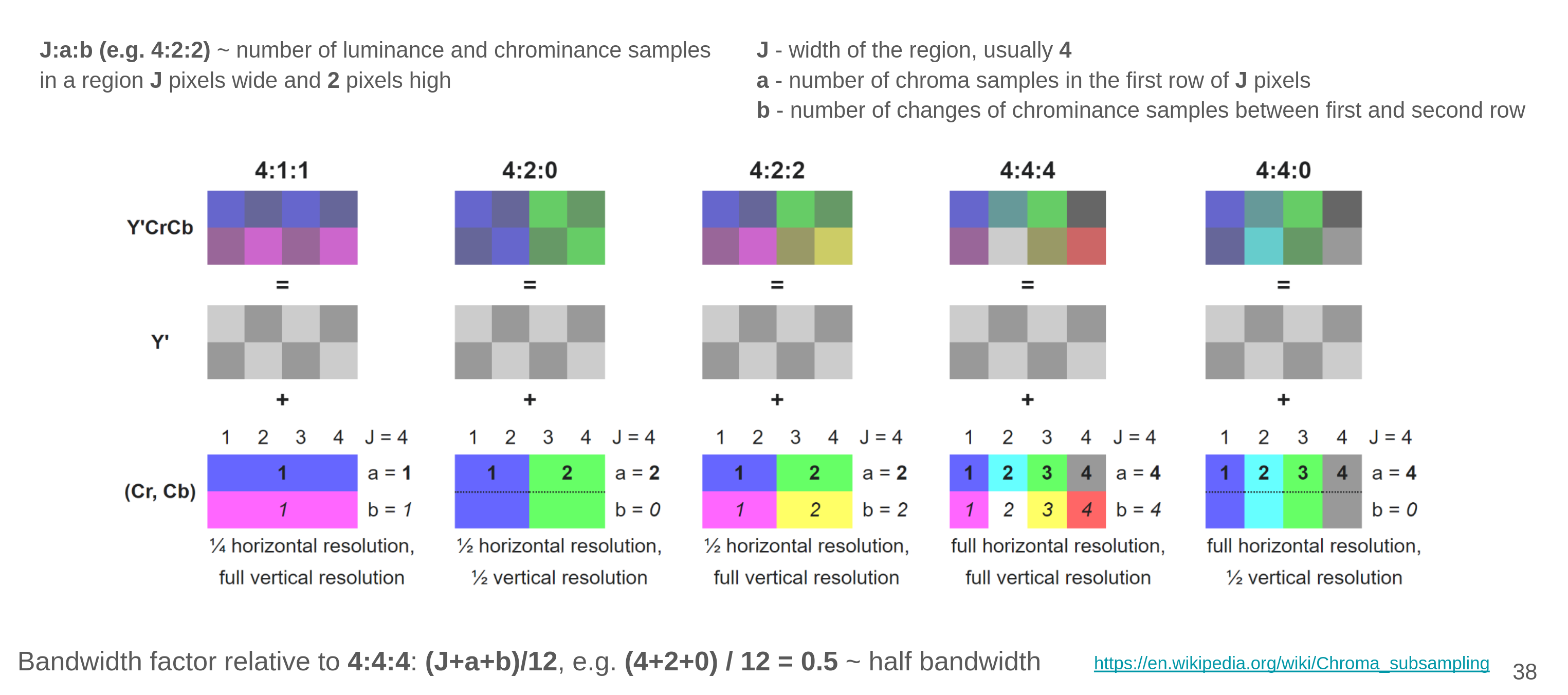
- using Y'CbCr model
- JPEG:
- converts RGB into Y'CbCr 4:2:0 subsample
- DCT = discrete cosine transform
- Quantization
- editors:
- GIMP
- Photoshop
- RAW:
- snap of information straight from the image sensor, needs to be processed later
Video formats
- simple approach - save all standalone images
- R210 format
- MJPEG (Motion JPEG) - compression of R210
- inter-picture prediction
- 16x16 macroblocks, finds where the blocks moves, keeps the steady blocks => reduces temporal redundancy
- H.261
- used for video calls
- based on DCT, Quantization, inter-picture prediction
- MPEG-1: Video CD
- I-frame - picture represented fully
- P-frame - predicted frame (only holds the diff from the previous image)
- B-frame - bidirectonal frame (same, but bidirectional)
- H.262, H.263
- interlaced video support (odd and even rows are loaded separately at doubled FPS)
- H.264
- global motion compensation
- most commonly used video format
- up to 8K video
- VP8, VP9
- open standard formats
- used by YouTube
Digital audio formats
- Pulse-code modulation
- analog signal amplitude is sampled at regural intervals
- quantized to the nearest value within a range of digital steps
- WAV
- Waveform Audio Format
- typical for uncompressed audio
- CD Audio
- FLAC
- lossless compression
- linear prediction compression
- run length encoding
- MP3, AAC
- lossy compression
- discards parts of sound considered beyond hearing capabilities of most humans
- based on DCT
- AAC is successor to MP3
- more flexible, more compression
- OPUS
- lossy compression, that has better compression and better sound in testing
Multi-media
Multimedia container format
- how to sync audio and video
- how to stream multimedia
- examples:
- JPEG, PNG, WAV, TIFF
- AVI, MPEG, MP4
Print formats
PostScript
- programming language for printers
- Polish notation
- usually with encapsulated bitmap preview
Portal Document Format (PDF)
- based on PostScript, each PDF page independent on each others
- represents complete description of a document
- PDF/A - archivation mode -> cant be encrypted, no JavaScript etc...